But, as anyone who has run an A/B test knows, you still have to wait for weeks in order to start getting statistical significant results about which version is better.
Download Free: A/B Testing Guide
We’ve been wondering if there’s a way to cut this wait period as well. Wouldn’t it be wonderful if there was a way to instantly know which version is going to win without waiting weeks or months for the data to arrive?
Can AI help?
The first research direction we turned to was the booming AI technology. You would have certainly heard about neural networks, machine learning, and data science. Could one such technique help us? If neural networks can drive cars today, perhaps they can also predict which website version is better?
Over the last few years, we tried several techniques and invested a lot of money in trying to get one of the AI techniques to work. We did make some progress when a couple of months ago, we launched an AI powered website copywriter that helped marketers come up with new alternative headlines, CTAs and product descriptions to test.
But, unfortunately, similar AI-based techniques didn’t perform satisfactorily on prediction of A/B test results. It seems driving cars, beating world Go champion and detecting tumors is an easier problem than predicting which website design is going to be a better choice.
Enter IA
As we were about to almost give up on our dream project, someone pointed us to the elephant in the room: astrology. Our first reaction was to dismiss this absurd suggestion immediately. We’re a skeptical bunch and there’s no place for such pseudoscience in a serious business like ours.
But we were desperate and decided to give this totally absurd idea one last shot. We were told that millions of people across the world predict all sorts of phenomena using techniques like horoscopes, or Tarot cards. If people are using a technique to predict whether their marriage will succeed or not, can’t it be used to predict whether A version is better than the B version?
After looking at the cost-benefit equation, we decided to do a small pilot. If, as we predicted, astrology didn’t work we’ll just lose some investment and time. However, if it did work, it’ll change the marketing and user research industry forever.
So, in all earnestness we kickstarted the pilot. After doing initial research on the most predictive astrology technique, we settled on Indian Astrology (IA). Particularly, we settled on parrot astrology. What gave us confidence in it was that there’s even a wikipedia page on it.

In parrot astrology, an astrologer lays out multiple options in front of a caged pet parrot. When the parrot is let out of the cage, it picks one of the options as the prediction. Simple and straightforward. We loved it already.
What we did for our pilot is the following:
- Take 100 A/B tests from our database where there was a clear, statistical significant winner (either A or B)
- Print their screenshots
- Recruit an Indian astrologer with a parrot and have the parrot pick between the pairs of screenshots across 100 trials (one for each A/B test)
Our null hypothesis was that the parrot wouldn’t be able to pick better than the random chance. That is, the parrot should pick the correct winner and the loser each roughly with a 50% chance.
However, to our astonishment, the parrot picked the winner 80 times out of 100. Using any standard binomial calculator (either frequentist or bayesian), you’ll quickly find out that the chances of that happening are close to nil. Indian Astrology really worked!

We’re obviously onto something here. We soon plan to write a scientific paper on this and submit our findings in a top journal. It’s all very exciting and mysterious. How does the parrot know which version works best? Well, we don’t know that but it shouldn’t prevent us from using the technique in the real world (just the same way we still don’t know why deep learning is so effective at various kinds of problems but it’s used widely).
Download Free: A/B Testing Guide
Get early access to parrot-powered A/B test prediction
We’re actively trying to scale the pilot with an eventual goal for making it available for all businesses in the world via simple user interface inside VWO or via an API. The main challenge is in finding enough parrots and making sure we’re doing this ethically. Once we do that, any business in the world will be able to rapidly converge on optimal user interface without the need to do any A/B testing.
We have some slots for people who want early access to this technology. If you want to give it a shot, email us here: [email protected]
Wait, what?
Well, didn’t we say we’re a skeptical bunch? It turns out there’s no scientific evidence that astrology works. Moreover, we strongly condemn caging of any bird or animal for anything other than clinical or medical research (even in clinical research, we wish computational and physical models increasingly replace actual animals).
If you were excited about the prospect of prediction of A/B test results, you’re not alone. We’re excited about the same thing and even though parrot-astrology doesn’t work, we’re committed to continue making progress towards helping business teams achieve a higher probability of success in each of their A/B tests.
After launching an AI powered website copywriter last year, we recently launched an AI powered heatmap predictor. After you enter your webpage URL, we take a screenshot and use deep learning to predict the distribution of clicks on the website. This can help you spot obvious dead zones or distractors on your website even before you make it live or use a heatmap tool on it.
This tool is free to use. So feel free to try it as many times on as many websites.
We’re sorry for giving you hope that you can get rid of A/B testing, but hope you had fun reading the post 
Happy April Fools day!
Had a laugh? Send me a note at [email protected]. I read and reply to all emails.
]]> I am Paras Chopra, founder & chairman of VWO. I am back with the 8th post in my fortnightly series outlining a new idea or a story on experimentation and growth. Hope you find it valuable.
I am Paras Chopra, founder & chairman of VWO. I am back with the 8th post in my fortnightly series outlining a new idea or a story on experimentation and growth. Hope you find it valuable.
Vaccines for Covid-19 have first developed a year ago, and finally, they’re here. What took them so long?
The answer to this question points to the most significant A/B test conducted in recent history: the clinical trials for ensuring vaccines are safe and effective against the Covid-19 virus.
Download Free: A/B Testing Guide
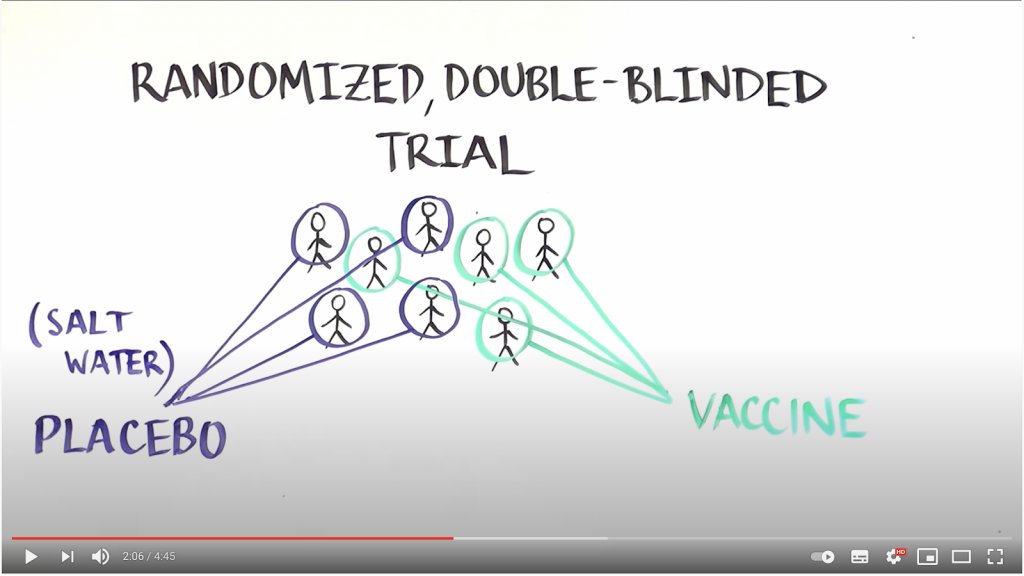
These clinical trials take so long because they’re divided into three phases, each testing a different aspect of the vaccine. This 3 stage design has taken shape over multiple decades, with thousands of scientists informing how it should be run.
Because human lives are at stake, clinical trials of vaccines are done very carefully. Be too hasty, and an unsafe vaccine can get released. But be too careful, and many more lives can be lost from the unchecked pandemic.
This trade-off leads to the thoughtful design of clinical trials of vaccines, and hence for the conversion optimization industry, there’s a lot to learn from it.
So, let’s see the three stages in which vaccines are tested and what we can learn from them for our own A/B tests.
Phase 1: Test for side-effects
Once developed in the lab and tested on animal models, in the first phase, a vaccine is tested on a small group of humans. The primary objective of this phase is to ensure the safety of the vaccine and check if there are any side effects from it.
Translating it to the A/B testing world, if you have a large change to make (say a homepage change, or a massive marketing campaign), the first thing you need to check for is not the positive impact of the change but for potential negative impact.
A variation that increases your clickthrough rate but ultimately decreases your business is no good. Hence, you should always have a set of business metrics (called guardrail metrics) which you never want to see getting reduced.
Phase 2: Test for effect-size
Once phase 1 is over, researchers enroll a bigger group and divide this group into multiple groups, with each group getting a different dosage level and one group getting no dosage at all (and instead of getting a placebo). You can think of this as an A/B/C/D test where the control means no change while different variations correspond to different dosage levels.
Volunteers belonging to different groups are then monitored over time to see whether the disease got cured or prevented while ensuring no major side effects.
The variation with minimum side effects and maximum benefits is declared a winner and then progressed to final phase 3 trials.
Phase 3: Large scale confirmatory test
By phase 2, there’s clear evidence that the vaccine seems to work, and researchers have discovered an appropriate dosage for it as well. However, the work isn’t done.
Researchers want to be doubly sure that the vaccine will work when released to the masses and hence in phase 3 significantly expand the number of people included in the test. Researchers actively seek out people from various previous conditions and age groups to ensure the sample they have is a good representation of the entire population.
This larger group is divided into two groups, and the final A/B test happens with one placebo and the winner dosage from the previous phase. This is the phase that takes the most amount of time and effort.
Download Free: A/B Testing Guide
Summing up: A/B testing works!
The trade-offs relating to human lives seen for testing vaccines aren’t likely to arrive in our businesses, but we all can learn from the rigorous manner in which scientists figure out things. Just like us, they’re humans too and want so badly for vaccines and other treatments to work. But they also know that the cost of a wrong vaccine can be devastating.
In the same spirit, I think it’s prudent to realize that even though we want our ideas to succeed so badly, we need to be careful about the possibility of such ideas making things worse for the business. A/B testing is the only way to ensure that they don’t.
If you have a story of an idea that you really wanted to work on, but it didn’t, I’d love to know about it. Send me a note at [email protected]. I read and reply to all emails.
]]> I am Paras Chopra, founder & chairman of VWO. Here is the 7th post in my fortnightly series outlining a new idea or a story on experimentation and growth. Hope you find it valuable.
Last week I interviewed Ian Harris, a professor of surgery, for my podcast. His research has found that over half of all surgeries are ineffective.
Yes, you heard that right: the majority of surgeries don’t work (as compared to a placebo). The list of what doesn’t work includes commonly done surgeries such as those done for knee pain, back pain, hip replacement, and so on. (If you don’t believe me, I highly recommend watching this talk by the professor.)
Download Free: A/B Testing Guide
This claim indeed sounds shocking, but recall that the most common surgical procedure in human history was bloodletting. In this practice that lasted for thousands of years and was common until the 1850s, the doctor would make a cut in the body and simply let out the blood of the patient.
Everyone thought this should work (partly because everyone did it) and many different variations of bloodletting were iterated and compared with each other. But, amazingly, a question that wasn’t asked until the 19th century was whether performing bloodletting works better than not doing it at all? Once this question was asked and a randomized control study was done, it was quickly understood that bloodletting doesn’t work (but may actually actively harm the patient).
Let me reiterate… bloodletting was performed for over 2000 years before it was discovered that it doesn’t work.
This makes you wonder – what else that we do commonly doesn’t actually work?
Actually, the sad part is that we don’t know what doesn’t work because, apart from medicine and science, we don’t perform enough randomized control trials (which are nothing but A/B tests in the marketing parlance). Even in the field of surgery, a systematic review of ~10,000 surgical procedures discovered that an A/B test was conducted for only 1% of such procedures. The remaining 99% of procedures were simply assumed to work.
In our day to day work as marketers, product managers, or leaders, we take so many decisions that feel right. Surely, that “best practice” change should work. Or this new campaign makes sense, so it should be run. But does it really work? What evidence do you have that if you hadn’t done anything, that metric wouldn’t have gone up?
Like the human body, businesses and markets are complex systems. There are thousands of factors that influence whether a particular action will have the desired impact. If the suggested action is our idea, we’re biased to believe that it works.
Download Free: A/B Testing Guide
However, learning from the ineffectiveness of bloodletting and many such surgeries that are still performed, the right attitude should be that best practices and genius ideas may simply not work (or, worse, may actively harm).
Unless a properly set up randomized control trial (or an A/B test) gives clear evidence of harm or benefit of a particular action, it would pay to believe that it probably doesn’t have any impact. The default orientation towards a new idea should be: no, it doesn’t work (unless you can prove that it works).
In other words, yes you should really be planning to run 25,000 A/B tests in 2021.
Do you have a story of an A/B test that debunked a widely held belief? I’d love to know about it. Send me a note at [email protected]. I read and reply to all emails.
]]> I am Paras Chopra, founder & chairman of VWO. This is the 6th installment of my fortnightly series outlining a new idea or a story on experimentation and growth. Hope you enjoy reading it!
There’s a company that has grown twice as fast as S&P 500. Beating the market consistently for more than 10 years proves that what they’re doing isn’t a fluke.
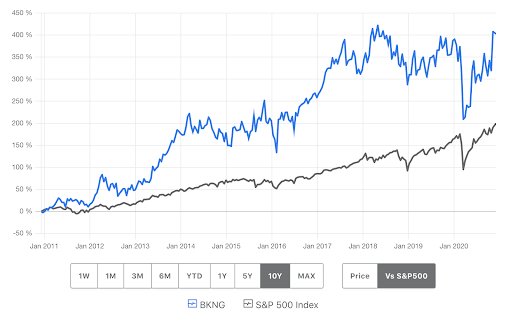
This company – whose stock price is shown as the blue curve in the graph above – must be having a secret sauce for growth.
Download Free: A/B Testing Guide
What is it?
Well, the company in question is Booking.com, and they are known for their culture of experimentation. They collectively run more than 25,000 A/B tests annually – which means they’re launching ~70 tests every single day. Sounds crazy, but according to their leadership, this A/B testing craziness is one of the critical ingredients in their growth.
To see how this culture of experimentation has played a role in their growth, look at their hotel listings page.
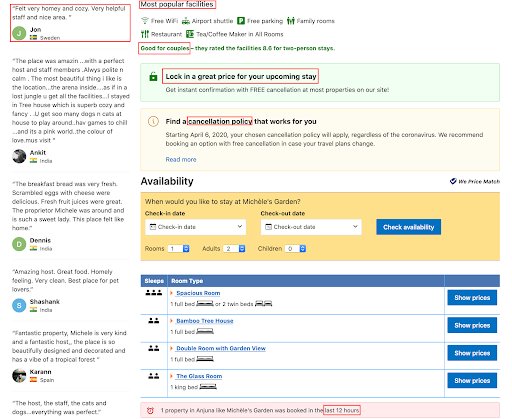
Everything highlighted on the listing page is there either because an A/B test found it made an impact on their business or is currently getting A/B tested. More importantly, everything that you don’t find on the page is not there because an A/B test proved that it actually hurt their business or made no difference.
To learn more about how Booking.com scaled its testing program to 25,000 tests a year, you can check these two resources:
- Harvard Business Review’s cover story on building a culture of experimentation
- VWO’s interview with Lukas Vermeer, Booking.com’s Director of Experimentation
So, how can you too run 25,000 tests this year?
Well, I understand that not every website has traffic levels of Booking.com. But if not 25,000 A/B tests a year, a site with one-hundredth of Booking.com’s traffic should at least be running one-hundredth the tests – say 250 tests a year, which is almost 20 tests a month.
Do you run 20 A/B tests a month? What about 10 per month?
Unless you’re an agency or an outlier company, my guess is that the answer would be no.
I see many businesses running occasional A/B tests, and if they have a program, they’d be perhaps launching 2-3 A/B tests a month. That’s about it. Finding exceptional cultures where experimentation is taken seriously is a rarity. But why?
I think the answer boils down to whether there’s a commitment from the leadership. Experimentation is hard. Coming up with ideas, setting up tests, investing in infrastructure, getting variants designed and coded, performing quality checks, and interpreting results take real effort. Combine this with the emotional cost of most experiments not working out. No wonder so many organizations just give up on it too soon.
Download Free: A/B Testing Guide
But giving up on experimentation is giving up on a high-leverage activity that can trigger business growth. This is because an increased conversion rate is only the most direct benefit of experimentation. A full commitment to experimentation transforms the entire culture:
- People in the org start trusting data more.
- A higher percentage of decisions start getting questioned on whether they’re someone’s pet projects or actual business-needle moving.
- You end up having fewer failed launches.
- And, the best part, the organization gets exposed to deliberate serendipity. Even if an A/B test didn’t win in the traditional sense, most A/B tests end up increasing the amount of insight the org has about customers and markets.
Leaders at Booking.com understand how easy it is to give up on experimentation, and that is why they’ve done things like:
- Enabling everyone in the org to launch an A/B test without gatekeepers.
- Having processes in place that ensure that no changes are made to any page until they’re A/B tested.
- Make experimentation evangelizing team report into the company’s leadership.
A culture that prioritizes understanding customers better than competitors is the real benefit that experiments create. The actual conversion rate increase is simply a nice cherry on top.
So, let me ask again: what would it take for your organization to launch more A/B tests in 2023 than it did in 2022? What’s preventing your organization from adopting experimentation as a central part of your growth strategy? Send me a note at [email protected]. I read and reply to all emails.
]]> I am Paras Chopra, founder & chairman of VWO. Here is the 5th post in my fortnightly series outlining a new idea or a story on experimentation and growth. Hope you are finding these useful.
I was talking to a colleague yesterday, and one of his offhand remarks struck a chord with me. We were chatting about how with A/B testing and experimentation, all the effort is upfront, but the reward is often much delayed.
His point was that while the reward of A/B testing is uncertain when it comes, it comes with a certificate stating that you’ve made a real and tangible difference to something that your business values.
Download Free: A/B Testing Guide
See, businesses are not complicated. They’re complex. Complicated problems are those where solutions are hard to find, but they exist. Complex problems are those where no solutions exist because the problem itself keeps changing, often in response to solving the problem.
Because there’s always so much going on in a typical business, attribution of what is causing what is just impossible. Did the metrics go up or down because the market is up or because you did something? This is impossible to know because, often, even when you’re not doing anything, metrics keep fluctuating by themselves.
In such a constantly swirling business landscape, the best way to demonstrate that you’re making a real difference to your organization is by A/B testing.
Remember: an uncontested proof of value creation is the most predictable way of getting a promotion.
So if you consider yourself an expert at your job but feel your efforts aren’t appreciated enough, in most cases, that’s not because of company politics or the boss not liking you. We’d like to believe that most organizations aren’t actively trying to hurt themselves by punishing their high performers. Often what’s happening is that the attribution of efforts to rewards in an org isn’t that straightforward.
But you don’t have to keep your career growth limited because of this. You can take charge of your career by taking charge of the A/B testing program at your organization (or starting to participate in it actively). You’ll not only be able to objectively demonstrate your expertise but if it’s the case that you’ve been overestimating your abilities, the wake of failed A/B tests will make you introspect and teach you what no boss or coach can ever teach you.
Download Free: A/B Testing Guide
So, net-net, as far as personal career growth is concerned, nothing beats A/B testing. If your A/B tests win, your impact on the organization becomes as clear as daylight. If your A/B tests lose, your drive for improving yourself will increase as the harsh truth helps you learn more about your strengths and areas of improvement.
If you have a story of an A/B test (or some metric) that got you a promotion, I’d love to know. Send me a note at [email protected]. I read and reply to all emails
 I am Paras Chopra, founder & chairman of VWO. Hope you are finding my fortnightly posts outlining a new idea or a story on experimentation and growth useful. Here is the 4th letter.
I am Paras Chopra, founder & chairman of VWO. Hope you are finding my fortnightly posts outlining a new idea or a story on experimentation and growth useful. Here is the 4th letter.
The rules of chess are easy to remember: a pawn moves one step forward, the queen can go anywhere and the end goal of the game is to protect the king. Once you remember the rules, the game is easy to set up and fun to play.
But being easy in principle doesn’t mean it’s also easy in practice. Truly mastering chess can take decades of daily practice and requires memorizing thousands of nuances about opening moves, closing moves, and opponent strategies.
Download Free: A/B Testing Guide
A/B testing is very similar to chess in that sense.

In principle, A/B testing is simple: you have two variations, each of which gets equal traffic. You measure how they perform on various metrics. The one that performs better gets adopted permanently.
In practice, however, each word in the previous paragraph deserves a book-length treatment. Consider unpacking questions like:
1/ What is “traffic” in an experiment?
Is it visitors, users, pageviews, or something else? If it is visitors, what kinds of visitors? Should you include all visitors on the page being tested, or should you only include the visitors for whom the changes being tested are most relevant?
2/ What is “measurement” in an experiment?
If a user landed on your page and did not convert, when do you mark it as non-conversion? What if the user converts after you’ve marked it as non-conversion? How do you accommodate refunds? If different user groups have markedly different conversion behavior, does it even make sense to group them during measurement? If you group them, how do you deal with Simpson’s paradox?
3/ What types of “various metrics” should you measure?
Should you have one metric to measure the performance of variations, or should you have multiple? If you measure revenue, should you measure average revenue per visitor, average revenue per conversion, 90th percentile revenue, frequency of revenue, or all of them? Should you remove outliers from your data or not?
Download Free: A/B Testing Guide
4/ What does “perform better” mean?
Is 95% statistical significance good enough? What if it is 94%? What if the new variation is not performing significantly better but feels it should? Do you take a bet on those? What if one metric improved but another that should have improved as well actually became worse? How real is Tyman’s law, which states that extreme improvements are usually due to instrumentation effort?
For the skeptic, these questions may seem like a needless pedantic exercise. But, without rigor, why bother doing A/B testing in the first place?
Nobody likes their ideas, and efforts go to waste, so we latch onto any glimmer of success we see in our A/B tests. It’s relatively easy to get successful A/B tests because it presents many avenues for misinterpretation to a motivated seeker. It’s only human to be biased.
But because of this lack of rigor in A/B testing, many organizations that get spectacular results from their A/B tests fail to see an impact on their business. Contrast this with organizations who take their experimentation seriously: Booking.com, AirBnB, Microsoft, Netflix, and many other companies with a culture of experimentation know that getting good at A/B testing takes deliberate commitment.
So, next time someone tells you that A/B testing doesn’t work, remind yourself that it’s like saying chess is a boring game just because you’re not good at it.
If you enjoyed reading my letter, do send me a note with your thoughts at [email protected]. I read and reply to all emails
I am Paras Chopra, founder & chairman of VWO. Every fortnight, on this blog and on our email list, I’ll be posting a new idea or a story on experimentation and growth. Here is my 3rd letter.
I recently finished reading a book on the history of the Bayes’ theorem (appropriately called the theory that would not die) and thought you may enjoy my notes from it.

1/ Statistics is all about calculating probabilities, and there are two camps who interpret probability differently.
- Frequentists = frequency of events over multiple trials
- Bayesians = subjective belief of the outcome of events
Download Free: A/B Testing Guide
2/ This philosophical divide informs what these two camps usually bother with.
- Frequentists = probability of data, given a model (of how data could have been generated)
- Bayesians = probability of model, given the data
3/ Most often we care about the latter question and that is what the Bayesian way of thinking helps with.
For example, given that the mammography test is positive, we want to know what the probability of having breast cancer is. And given breast cancer, we usually don’t care about the probability of the test being positive.
4/ These two questions sound similar but have different answers.
For example, imagine that 80% of mammograms detect breast cancer when it’s there and ~90% come out as negative when it’s not there (which means for 10% times it comes as positive even if it’s not there).
Then if only 1% population has breast cancer, the probability of having it given a positive test is 7.4%.
5/ Read that again:
80% times the mammography test works and yet if you get a positive, your chances of having breast cancer are only 7.4%.
How is it possible?
6/ The math is simple:
- Chances that the test is positive when a patient has breast cancer = chances of detecting breast cancer when a patient has it * chances of having breast cancer in the first place = 80% * 1% = 0.8%
- Chances that test is positive when a patient does NOT have breast cancer = chances of detecting breast cancer when a patient DOESN’T have it * chances of NOT having breast cancer in the first place = 10% * 99% = 9.9%
Now, the chances of having breast cancer on a positive mammogram are simply:
% times you get a positive mammogram if you have breast cancer / % times you can get a positive mammogram.
We calculated these numbers above, so this becomes
0.8%/(0.8%+9.9%) = 7.4%.
Voila! So even if a test works 80% of the times, it may not be very useful (if population incidence rate is low, which is 1% in this case). This is why doctors recommend taking multiple tests, even after a positive detection.
7/ When you understand Bayes’ theorem, you realize that it is nothing but arithmetic.
It’s perhaps the simplest but most powerful framework I know. If you want to build a better intuition about it, I recommend reading this visual introduction to Bayes’ theorem (which also contains the breast cancer example we talked about).
Download Free: A/B Testing Guide
8/ The key idea behind being a Bayesian is that *everything* has a probability.
So instead of thinking in certainties (yes/no), you start thinking about chances and odds.
9/ Today, Bayes’ theorem powers many apps we use daily because it helps answer questions like:
- Given an e-mail, what’s the probability of it being spam?
- Given an ad, what’s the probability of it being clicked?
- Given the DNA, is the accused the culprit?
- And, of course, given the data, is variation better than the control in an A/B test? (FYI – we use Bayesian statistics in VWO)
10/ That’s it! Hope you also fall in love with the Bayesian way of looking at the world.
If you enjoyed reading my letter, do send me a note with your thoughts at [email protected]. I read and reply to all emails
I am Paras Chopra, founder & chairman of VWO. This is my 2nd letter in the fortnightly series with a new idea or a story on experimentation and growth.
“All models are wrong, but some are useful”.
What did the British statistician George Box mean when he wrote these now-famous words in 1976, and how is it relevant to you?
Whenever we try understanding the world around us – be it our customers’ behavior, or how stars circle the center of a galaxy, or how coronavirus affects the human body – we never have direct and full access to the underlying reality. Instead, what we have access to is only the data generated by the process that we want to understand.
So, for example, we know that a customer clicked on one button but ignored the other one. Based on this data point, we now infer what sort of customer she must be and predict her needs are and how we can fulfill them.
Download Free: A/B Testing Guide
Notice that the data hasn’t told you a lot – it’s sterile, a mere bunch of numbers. But when you combine the fact that a customer clicked on the button with your assumptions about how people behave, you get the magical ability to predict the future (which you can use to your advantage).
But your assumptions are not equal to reality and that’s why Box said: “all models are wrong”. To understand this clearly, look at the following chart:
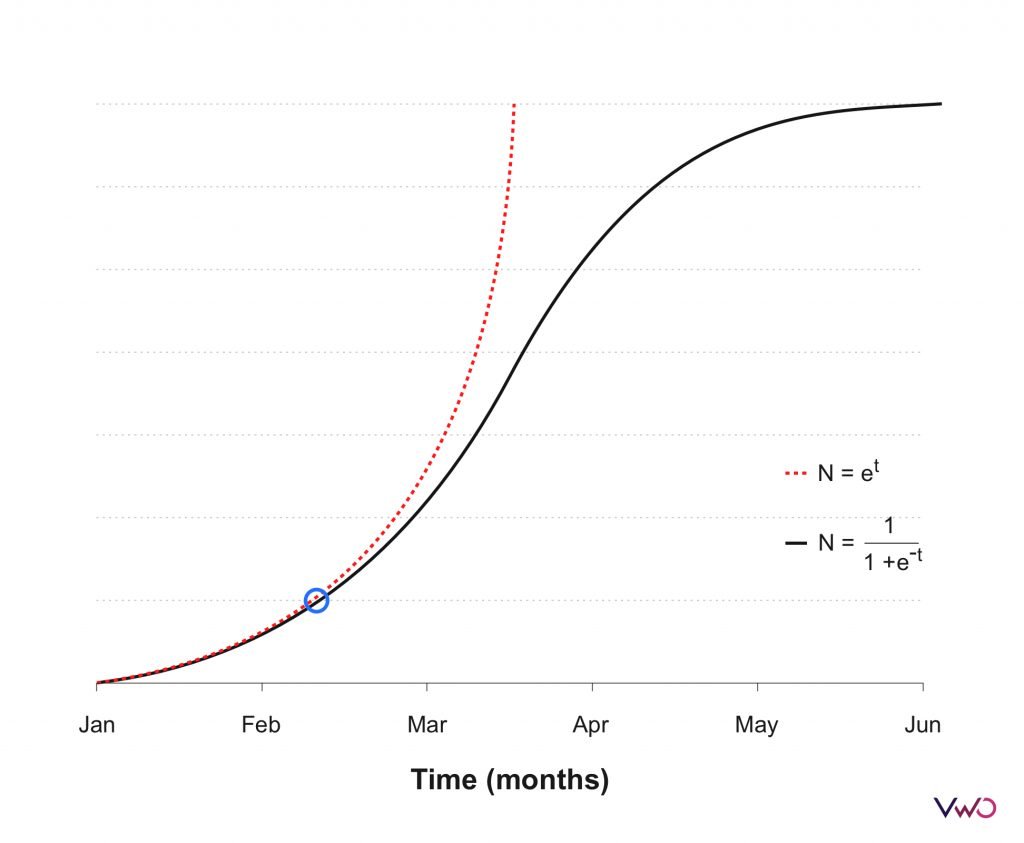
Imagine you start observing the data from the start (the bottom left) and you move in time and collect more data points (up to the blue circle). At this stage, you have to decide whether future data points will lie on the red curve or the black curve. Perhaps you have to make a business decision based on this choice. Which one will you pick?
Actually, in this case, even though black and red curves are generated through two very different realities (see their equations), there’s no way any amount of historical data can help you choose because all data up to blue circle is consistent with both.
As you can see data cannot help you select between hypotheses, it can only help you eliminate. The idea that theories can never be proved true, but only be shown to be wrong is core to how science is done. So scientists definitely know which theories are wrong, but they never know for certain which theories are right. (Surprisingly, that’s also how venture capitalists work: while investing, they know for sure which companies are “duds” but they never know which ones are going to be “unicorns”).
Box also said: “some (models) are useful”. Notice that he didn’t say some models are correct. He used the term “useful”.
Download Free: A/B Testing Guide
The usefulness of models points to their ability to predict the future. Scientific laws (like Newton’s law of gravitation) are models that help us predict solar eclipses hundreds of years ahead. They work quite well for this purpose while another model like throwing darts to predict eclipses will fail horribly. So even though both models are wrong, Newton’s law gives us more mileage because it’s proven to be useful in a variety of contexts.
The key points to remember:
- Don’t shoot for being right because there’s no such thing as the “correct” assumptions. Shoot for having “useful” assumptions.
- Data alone is sterile. Whenever you think data is giving you insights, it’s actually the data+your assumptions that are informing you.
If you enjoyed reading my letter, do send me a note with your thoughts at [email protected]. I read and reply to all emails
I am Paras Chopra, founder & chairman of VWO. Every fortnight, on this blog and on our email list, I’ll be posting a new idea or a story on experimentation and growth.
Twyman’s law states that any data or figure that looks interesting or different is usually wrong.
Sounds unbelievable, isn’t it?
But, it’s true. I saw this in action recently and wanted to share that story with you.
In June, we ran a test on our homepage and while I was looking at conversion rate by segments, I noticed that users from Windows had a 400% higher signup rate for VWO free trial as compared to users using Mac OS X.
Download Free: A/B Testing Guide
Now, that’s baffling and our team spent a good deal of time trying to understand why that was happening. Someone in marketing hypothesized that perhaps Mac OS X users have a better design aesthetic and our homepage wasn’t appealing to them. Was it true?
When we dug into data, we realized that our recently installed automated QA service creates signups on the homepage every hour or so (to ensure the form doesn’t stop working) and guess what, that automated service used Windows.
After removing such QA signups from data, Mac OS X and Windows conversion rate became comparable.
This is a perfect example of Twyman’s law. Remember, if the data is too good to be true, it’s probably wrong.
Many extreme results are likely to be the result of an error in instrumentation (e.g., logging), loss of data (or duplication of data), or a computational error.
Hope this mental model was new to you (it certainly was to me!).
PS: If you also have a story related to exaggerated data to share, email me at [email protected]. I read and reply to all emails
PPS: If you want to learn more about Twyman’s law, Ronny from Bing’s experimentation team spoke about it in his talk.
]]>